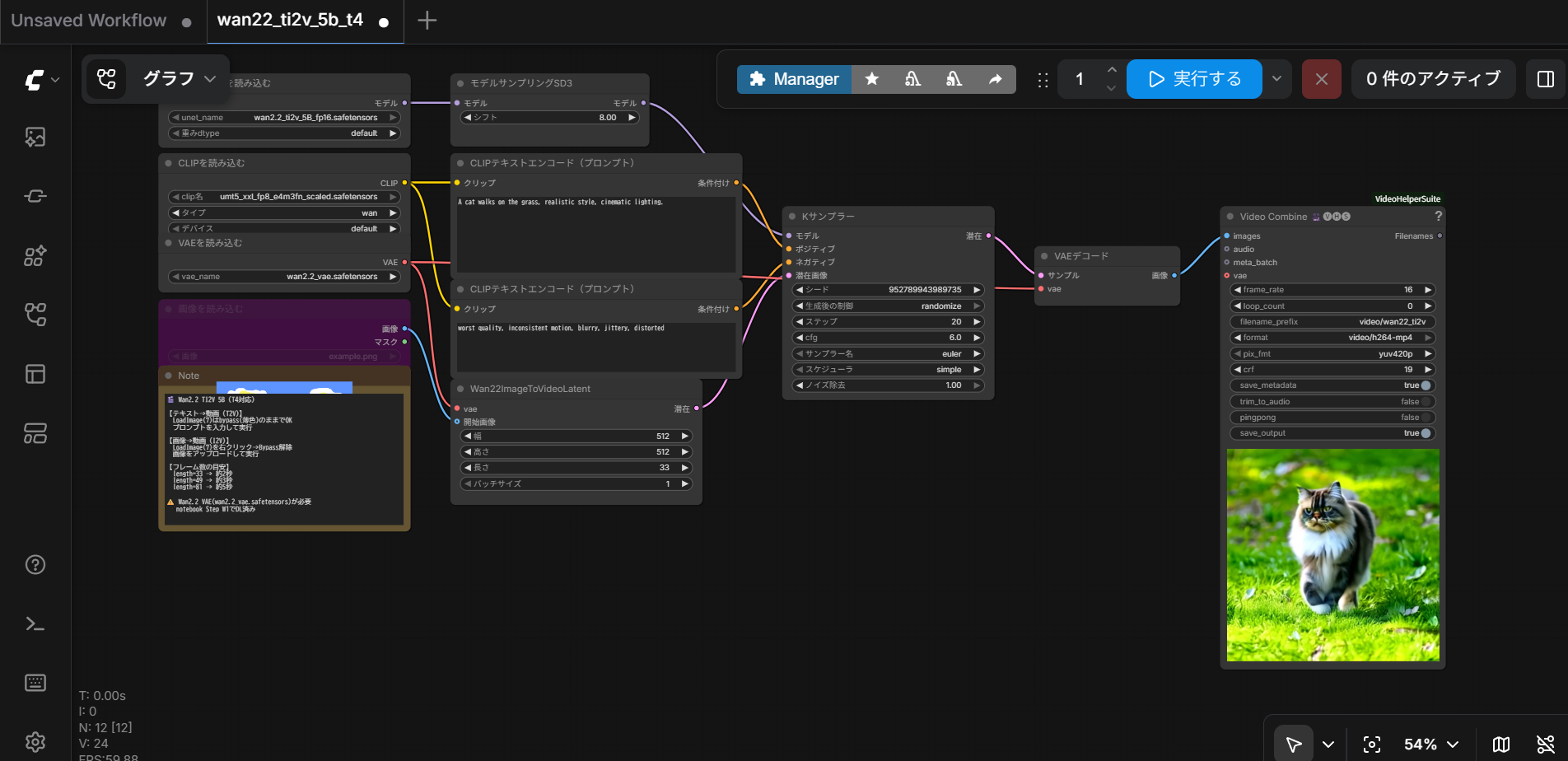
ComfyUiについての動画生成の場合です。
テンプレートから作成例を参照できます。
以下のボタンでcolabで起動します。(ユーザーアカウントが必要)
colabのT4用に制限しています。
Wan
Wan2.1 T2V 1.3B
Wan2.1 T2V 1.3B とは
Alibaba が2025年2月に公開したオープンソースの動画生成モデルです。14B と 1.3B の2種類があり、オープンウェイトモデルのリーダーボードでトップクラスの評価を受けています。 Hunyuan3D AI
特徴:
必要VRAMは約8GBで、コンシューマー向けGPUで動作します。RTX 4090では最適化なしで5秒の480P動画を約4分で生成できます。 Hunyuan3D AI
世界初の動画内での日本語・中国語・英語テキスト生成に対応しています。またWan-VAEは1080Pの任意の長さの動画をエンコード・デコードできます。 Hunyuan 3D
1.3B と 14B の違い
項目 1.3B(現在使用中) 14B 必要VRAM 約8GB(T4で余裕あり) 約24GB以上 解像度 480P推奨(720Pは不安定) 480P・720P両対応 タスク テキスト→動画のみ テキスト→動画、画像→動画 品質 良好 より高品質 ライセンス Apache 2.0 Apache 2.0 1.3Bモデルは720P解像度の動画生成も可能ですが、学習データが少ないため480Pの方が安定した結果が得られます。 GitHub
拡張モデル(参考)
1.3Bをベースにした派生モデルが多数あり、LoRA学習、動画編集(Wan-Edit)、マルチキャラクター生成(EchoShot)、ポーズ制御アニメーション(HyperMotion)などが公開されています。 Hunyuan3D AIまたVACE(Video Creation and Editing)という全機能統合モデルも2025年5月に公開されています。 Hunyuan3D AI
T4(16GB)では現在の1.3Bが最適な選択です。品質をさらに上げたい場合はA100(40GB以上)で14Bモデルを使う形になります。
08 (wan2.1動画生成)のcolabで生成実行
jsonファイル:
wan21_t2v_t4_v6.jsonwan2.2
Wan2.2 とは
MoE(Mixture of Experts)アーキテクチャを動画生成拡散モデルに初めて適用したモデルで、ComfyUIはDay-0でネイティブサポートを達成しました。高ノイズ専門モデルと低ノイズ専門モデルに分かれており、ノイズ除去の段階に応じて専門モデルを使い分けることで高品質な動画を生成します。 DeepWiki
Wan2.1 との主な違い
| 項目 | Wan2.1 | Wan2.2 |
|---|---|---|
| アーキテクチャ | Dense | MoE(専門家混合) |
| 学習データ | 基準 | 画像+65.6%、動画+83.2% |
| 映像品質 | 良好 | プロ映画水準の色彩・構図制御 |
| モデル種類 | T2V, I2V | T2V, I2V, TI2V(テキスト+画像→動画), S2V(音声→動画) |
T4で使えるモデル
Wan2.2 TI2V-5BはVRAM 8GB以上で動作し、T4(16GB)に最適です。720P・5秒の動画を1枚のコンシューマーGPUで9分以内に生成できます。テキスト→動画と画像→動画の両方を1つのモデルで対応しています。 Hugging Face
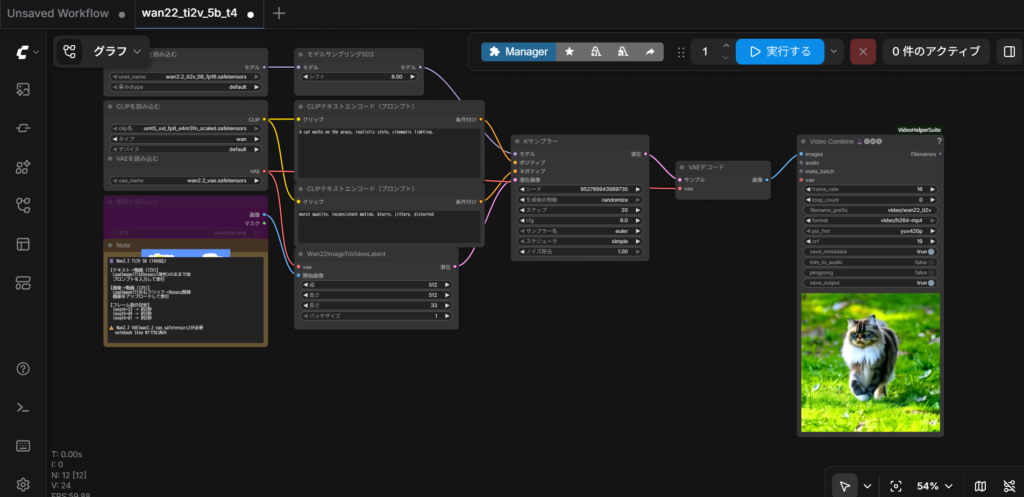
09 (wan2.2動画生成)のcolabで生成実行
jsonファイル:
wan22_ti2v_5b_t4.jsonwan2.2 画像プロンプト
画像入力を含めた場合
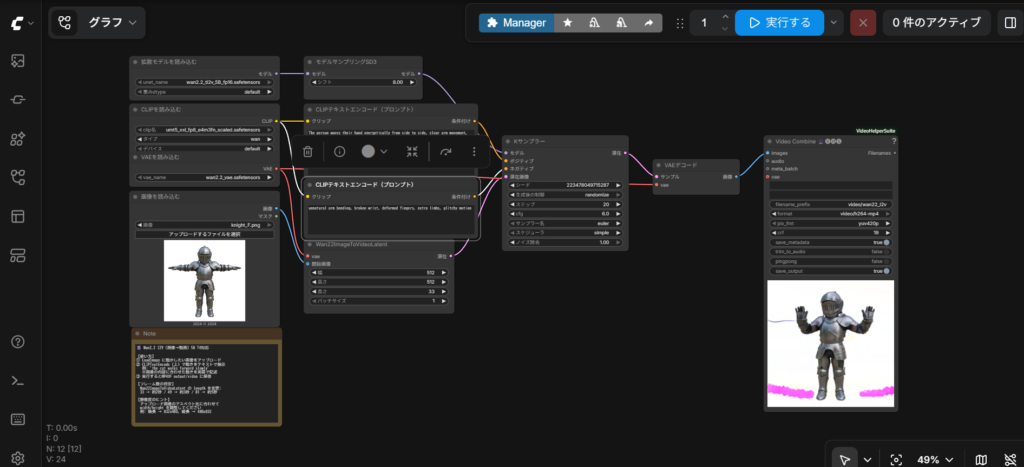
09 (wan2.2動画生成)のcolabで生成実行
jsonファイル:
wan22_i2v_5b_t4_1.json
コメント