ComfyUiについての画像生成の覚書です。
チュートリアルに例題があります。

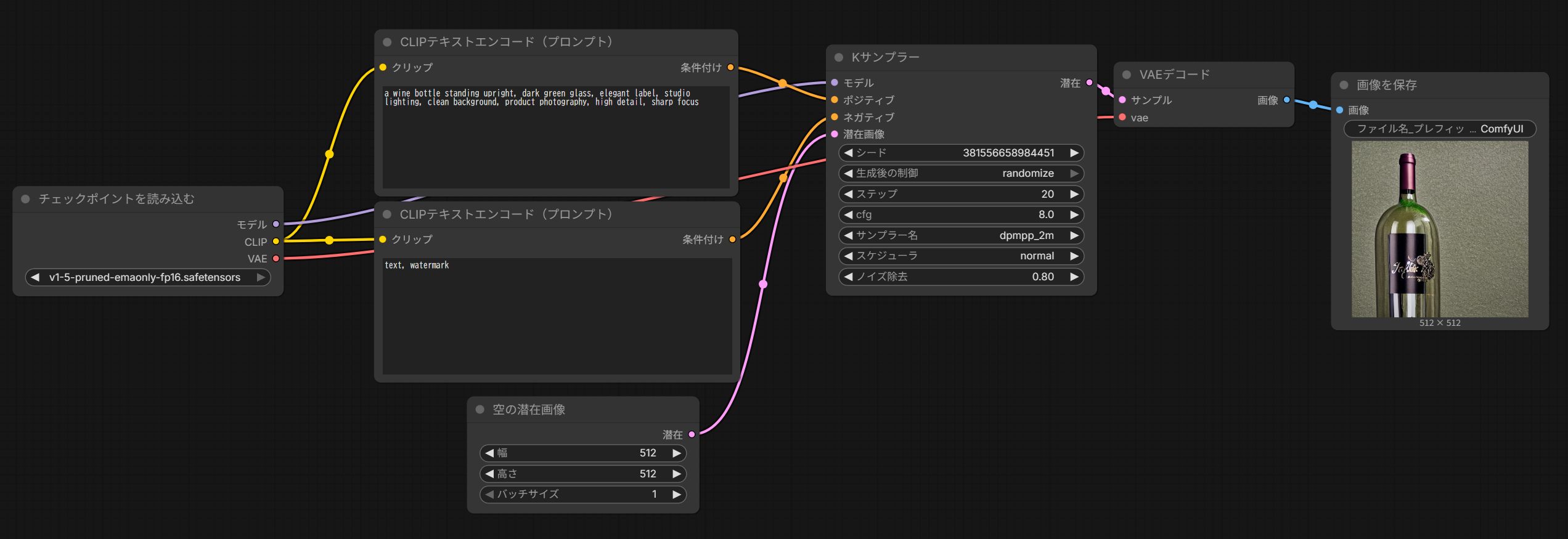
Text to Image チュートリアル
ComfyUIでテキストプロンプトから画像を生成(Text to Image)する際の要点は、大きく分けて**「プロンプトの記述ルール」、「主要ノードの役割の理解」、そして「生成を制御するパラメーターの設定」**の3つに集約されます。
1. プロンプトの記述ルール
プロンプトは、生成したい要素を指定する「ポジティブプロンプト」と、除外したい要素を指定する「ネガティブプロンプト」の2種類を使い分けます。特にSD1.5モデルを使用する場合、以下の原則が推奨されます:
• 言語と形式: 可能な限り英語を使用し、長い文章ではなく短いフレーズを**カンマ(,)**で区切って入力します。
• 具体性: 抽象的な表現よりも具体的な説明を行い、「masterpiece」「best quality」「4k」といったキーワードを加えることで品質を向上させることができます。
• 重み付け: 特定のキーワードを強調したい場合は、(キーワード:重み) という形式(例: (golden hour:1.2))を使用します。
2. 主要ノードの役割
ワークフローを構成する各ノードには、画像生成プロセスにおける明確な役割があります:
• Load Checkpoint: 生成の核となるモデル(MODEL、CLIP、VAEのセット)を読み込みます。
• Empty Latent Image: 画像の「キャンバスサイズ(解像度)」を決定し、最初は純粋なノイズの状態である「潜在空間(Latent Space)」を定義します。
• CLIP Text Encoder: 人間が書いたテキストを、モデルが理解できる形式(セマンティックベクトル)に変換します。
• KSampler: ワークフローの核心部であり、プロンプトの指示に従って**ノイズを除去(デノイズ)**し、画像を形成していきます。
• VAE Decode: 潜在空間上のデータを、私たちが目に見える「ピクセル空間(Pixel Space)」の画像に変換します。
3. 生成を制御する重要パラメーター
KSamplerノードにある設定値を調整することで、生成結果をコントロールできます:
• Seed: ノイズの初期状態を決める数値です。同じシード値なら同じ画像が生成され、値を変更すれば異なる結果が得られます。
• Steps: デノイズを繰り返す回数です。回数が多いほど細部が描き込まれますが、処理時間は長くなります。
• CFG (Classifier-free guidance): プロンプトの指示にどれだけ忠実に従うかを調整します。値が高すぎると画像が破綻(オーバーフィッティング)することがあります。
• Denoise: 潜在空間にどれだけノイズを加えるかの係数です。Text to Imageでは通常「1.0(完全なノイズからの生成)」を使用します。
ComfyUIでの画像生成は、「設計図(プロンプト)」を手に、熟練の「芸術家(モデル)」が、真っ白な「キャンバス(潜在空間)」の上に、少しずつ霧を晴らすように(デノイズ)絵を描いていく作業に例えることができます
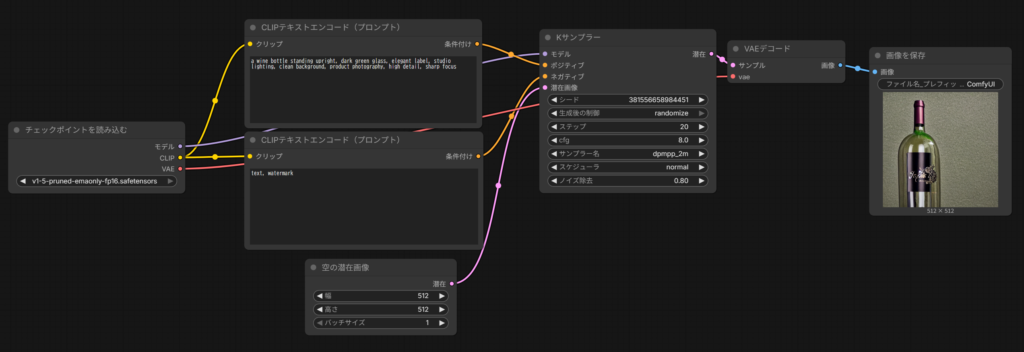
Image to Image チュートリアル
画像から画像を生成する(Image to Image)ワークフローにおいて、最も重要な要点はKSamplerノードの「denoise(デノイズ)」パラメータの調整です。
1. 「denoise」パラメータの制御がカギ
Image to Imageの成功は、この数値の設定にかかっています。denoiseの値は必ず「1未満」に設定する必要があります。
• 値を小さくする(0に近い): 生成される画像と元の参照画像の差が小さくなります。元の構図やディテールを強く残したい場合に適しています。
• 値を大きくする(1に近い): 元の画像との差が大きくなり、AIによる改変が強まります。
• 値が1の場合: 潜在空間(Latent Space)の画像が完全にランダムなノイズに置き換わるため、参照画像の特徴がすべて失われます。これはText to Image(テキストからの生成)と同じ状態になってしまいます。
2. 基本的なワークフローの構成
Image to Imageは、Text to Imageのプロセスに「参照画像」という条件を追加したものです。
• Load Imageノード: 参照したい画像をアップロードします。
• Load Checkpointノード: 使用するモデル(例:v1-5-pruned-emaonly-fp16.safetensors)をロードします。
• プロンプト: テキストのみで自由に描かせるのではなく、「参照画像」と「プロンプト」の両方を条件としてAIに指示を出します。
3. Image to Imageの活用例
この手法は、単なる画像生成だけでなく、以下のようなシナリオで効果を発揮します:
• スタイルの変換: 実写の写真をアート風やアニメ風に変換する。
• 線画の具体化: ラフな線画からリアルな画像を生成する。
• 画像の修復・着色: 古い写真の復元や、モノクロ写真への色付け。
例えるなら: Text to Imageが画家に「自由に絵を描いて」と頼む作業だとすれば、Image to Imageは**「この手本(参照画像)を参考にしながら、私の指示(プロンプト)に従って新しい絵を描いて」**と頼むようなものです。手本をどれくらい忠実に守るかを決めるのが「denoise」というツマミの役割です。
Lora
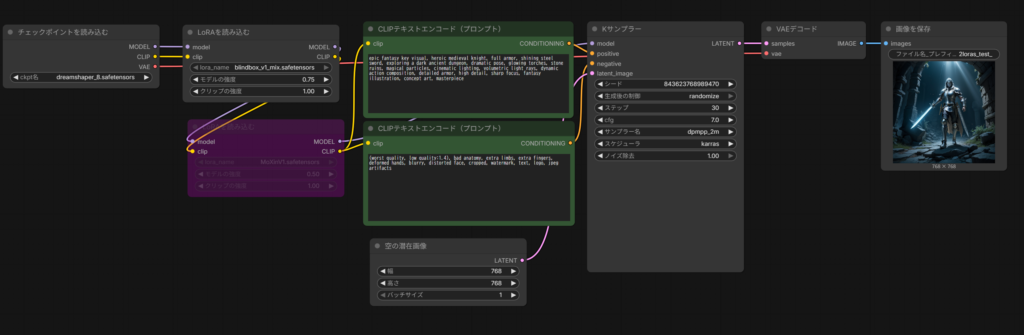
DreamShaper 8(ベースモデル)+ blindbox_v1_mix(画風 LoRA)+ MoXinV1(キャラ LoRA)
🧩 このワークフローの LoRA 構成の全体像
✔ ベースモデル
DreamShaper 8
→ ファンタジー・アニメ・リアルの中間で、ゲームアートに強い万能モデル
✔ LoRA 1
blindbox_v1_mix(強度 0.75 / 1.0)
→ 色彩・雰囲気・画風を整える“画風 LoRA”
✔ LoRA 2
MoXinV1(強度 0.5 / 1.0)
→ 顔立ち・線の柔らかさ・可愛さを追加する“キャラ LoRA”
この 2 つを DreamShaper に重ねることで、
「柔らかいアニメ調 × ファンタジー × キャラ映え」
という独特の画風が生まれる。
🔧 ⑦ LoRA の強度調整の目安
✔ もっとリアル寄りにしたい
- blindbox:0.5
- MoXinV1:0.3
✔ もっとアニメ寄りにしたい
- blindbox:1.0
- MoXinV1:0.7
✔ 騎士の硬派さを出したい
- MoXinV1 を弱める(0.3〜0.4)
- blindbox を強める(0.8〜1.0)
lindbox → MoXinV1 の二段階 LoRA 適用
🧩 二段階 LoRA の最適設定(blindbox → MoXinV1)
🛡️ ① blindbox_v1_mix(画風 LoRA)
🎨 役割
- 色彩を鮮やかにする
- コントラストを整える
- イラスト調の統一感を出す
⚔️ ② MoXinV1(キャラ LoRA
🎨 役割
- 顔立ちを整える
- キャラの魅力を上げる
✔ ① LoRA は“適用順”がとても重要だから
ワークフローでは、LoRA がこの順番で読み込まれている:
- blindbox_v1_mix(LoRA 1)
- MoXinV1(LoRA 2)
ComfyUI は 上から順番に LoRA をモデルへ合成していくため、
この順番がそのまま「呼び名」や「構成名」になる。
つまり:
ベースモデル(DreamShaper)に blindbox を重ね、
その上に MoXinV1 をさらに重ねる構造
になっている。
✔ ② 先に適用された LoRA が“土台の画風”を作る
blindbox が先に適用されると:
- 色彩
- コントラスト
- 線の雰囲気
- イラスト調の統一感
といった 画風のベースが決まる。
その後に MoXinV1 を重ねることで:
- 顔の可愛さ
- 目の大きさ
- 柔らかい線
- キャラの雰囲気
といった キャラ特性が追加される。
だから順番はとても重要で、
blindbox → MoXinV1 という呼び方になる。
✔ ③ LoRA の順番が変わると絵の雰囲気も変わる
例えば逆にすると:
MoXinV1 → blindbox
- キャラの顔が先に決まり
- blindbox が後から画風を上書きする
→ キャラの可愛さが薄れたり、線が変わったりする
つまり LoRA の順番は“どの要素を優先するか”を決めるんだ。
あなたの構成は:
- blindbox(画風)
- MoXinV1(キャラ)
という順番なので、
画風 → キャラの顔
という自然で安定した流れになっている。
✔ ④ ComfyUI の LoraLoader が“順番通りにモデルを更新する”ため
ワークフローを見ると:
CheckpointLoaderSimple → LoraLoader(blindbox) → LoraLoader(MoXinV1)
という 直列構造になっている。
ComfyUI はこの順番でモデルを更新するため、
自然と blindbox → MoXinV1 という呼び方になる。
| 項目 | 内容 |
|---|---|
| LoRA の順番 | blindbox → MoXinV1 |
| 理由① | LoRA は適用順で効果が変わる |
| 理由② | blindbox が画風、MoXinV1 がキャラを担当 |
| 理由③ | ComfyUI が上から順に LoRA を合成する |
| 結果 | 「blindbox → MoXinV1」という呼び名になる |
作成確認
プロンプト
| positive | anime style, epic fantasy key visual, heroic medieval knight, shining steel sword, dynamic pose, exploring a glowing ancient dungeon, dramatic anime lighting, bright colors, clean line art, volumetric light rays, magical particles, detailed armor, expressive anime eyes, cinematic composition, high detail, masterpiece illustration |
| negative | (worst quality, low quality:1.4), bad anatomy, extra limbs, extra fingers, deformed hands, blurry, distorted face, cropped, watermark, text, logo, jpeg artifacts, overly realistic texture, harsh shading |

モデルの強度 0.75
クリップの強度 1
MoXinV1
モデルの強度 0.5
クリップの強度 1

モデルの強度 1
クリップの強度 1
MoXinV1
モデルの強度 0.6
クリップの強度 1

モデルの強度 0.75
クリップの強度 1
MoXinV1
モデルの強度 0.5
クリップの強度 1

モデルの強度 0.1
クリップの強度 0.5
MoXinV1
モデルの強度 0.1
クリップの強度 0.5

モデルの強度 0.1
クリップの強度 1
MoXinV1
モデルの強度 0.1
クリップの強度 1
プロンプト
| positive | anime style, cel shading, anime cel style, flat colors, bold outlines, two-tone shading, sharp shadow edges, vibrant anime color palette, clean line art, simplified textures, epic fantasy key visual, heroic medieval knight, shining steel sword, dynamic pose, exploring a glowing ancient dungeon, dramatic anime lighting, volumetric light rays, magical particles, detailed armor, expressive anime eyes, cinematic composition, high detail, masterpiece illustration |
| negative | overly detailed textures, realistic skin pores, photorealistic shading |

モデルの強度 0.1
クリップの強度 1
MoXinV1
モデルの強度 0.1
クリップの強度 1
コメント